Introduction
In the grand tapestry of artificial intelligence (AI), large models shine like brilliant stars, illuminating the future of technology. They not only reshape our understanding of technology but also quietly trigger transformations across countless industries. However, these intelligent technologies are not without their risks and challenges. In this article, we will unveil the mysteries of large models, sharing their technologies and characteristics, analyzing their development and challenges, and offering a glimpse into the AI era.

Large models, such as the Generative Pre-trained Transformer (GPT) series, have achieved remarkable success in the field of natural language processing (NLP), setting new performance benchmarks in various language processing tasks. Beyond language, large models also demonstrate significant advantages in image processing, audio processing, and physiological signals. They have rapidly found applications in fields like education, healthcare, and finance, particularly excelling in content generation. Today, numerous cutting-edge technologies related to large models are still in urgent need of development, while issues such as bias and privacy breaches require immediate attention. This article analyzes the past and present of large models, discusses pressing issues, and explores future directions, helping the public quickly understand large model technology and its development, integrating into the tide of the AI era.
![]()
Origins of Large Models
In November 2022, the renowned AI research company OpenAI released ChatGPT, an AI chatbot program based on the large language model GPT-3.5. Its fluent language expression, powerful problem-solving abilities, and vast database garnered widespread attention worldwide. Within less than two months of its launch, ChatGPT surpassed 100 million monthly active users, becoming the fastest-growing consumer application in history. As a result, various industries began to feel the powerful impact of large models, sparking a research boom in large models both domestically and internationally.
The origins of large models can be traced back to the early AI research in the 20th century, which primarily focused on logical reasoning and expert systems. However, these methods were limited by hard-coded knowledge and rules, making it difficult to handle the complexity and diversity of natural language. With the advent of machine learning and deep learning technologies, along with rapid advancements in hardware capabilities, the training of large-scale datasets and complex neural network models became possible, giving rise to the era of large models.
In 2017, Google’s introduction of the Transformer model structure, which incorporated self-attention mechanisms, significantly enhanced the ability to model sequences, especially in terms of efficiency and accuracy when handling long-distance dependencies. Subsequently, the concept of pre-trained language models (PLMs) gradually became mainstream. PLMs are pre-trained on large-scale text datasets to capture general patterns of language and are then fine-tuned for specific downstream tasks.
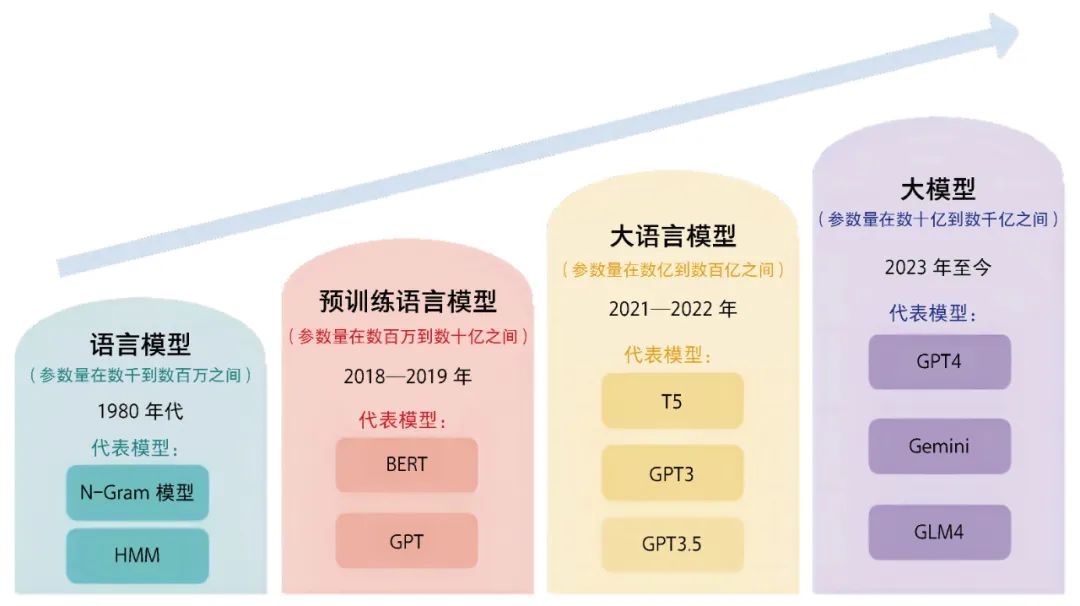
Evolution of Large Models
OpenAI’s GPT series models exemplify generative pre-trained models, representing the vanguard of this technology. From GPT-1 to GPT-3.5, each generation has seen significant improvements in scale, complexity, and performance. At the end of 2022, ChatGPT emerged as a chatbot capable of answering questions, writing articles, programming, and even mimicking human conversational styles. Its almost omnipotent answering ability has reshaped people’s understanding of the general capabilities of large language models, greatly advancing the development of the NLP field.
However, the development of large models is not limited to text. With technological advancements, multimodal large models have begun to emerge, capable of simultaneously understanding and generating various types of data, including text, images, and audio. In March 2023, OpenAI announced the multimodal large model GPT-4, which added image functionality and improved language understanding capabilities, marking an important shift from unimodal to multimodal models. The inherent differences between cross-modal data present new and more complex requirements for the design and training of large models, along with unprecedented challenges.
![]()
Characteristics of Large Models
Large models typically refer to machine learning models with vast parameter counts, especially in applications within NLP, computer vision (CV), and multimodal fields. These models understand and learn human language through pre-training, enabling them to perform tasks such as information retrieval, machine translation, text summarization, and code generation in a human-machine dialogue format.
Parameter Count of Large Models
The parameter count of large models usually exceeds 1 billion, meaning the model contains over 1 billion learnable weights. These parameters form the foundation for the model’s learning and understanding of data, continuously adjusted through training to better map input data to output results. The increase in parameter count is directly related to the model’s learning ability and complexity, enabling it to capture finer and deeper data features.
Types of Large Models
Large models can be classified based on their application areas and functions:
- Large Language Models: Focused on processing and understanding natural language text, commonly used for text generation, sentiment analysis, and question-answering systems.
- Visual Large Models: Specifically designed to process and understand visual information (such as images and videos), used for tasks like image recognition, video analysis, and image generation.
- Multimodal Large Models: Capable of processing and understanding two or more different types of input data (e.g., text, images, audio), performing more complex and comprehensive tasks by integrating information from different modalities.
- Foundation Large Models: Generally refer to models that can be broadly applied to various tasks without a specific application direction during the pre-training phase, learning a vast amount of general knowledge.
Capabilities of Large Models
The capabilities of large models lie in their ability to understand and process highly complex data patterns:
- Generalization Ability: Through pre-training on large datasets, large models learn universal linguistic rules, demonstrating strong generalization abilities when faced with new tasks.
- Deep Learning: The vast parameter scale and deep network structure enable large models to establish complex abstract representations, understanding the deeper semantics and relationships behind the data.
- Context Understanding: In language models, large models can capture long-distance dependencies, enhancing their ability to understand context, which is crucial for grasping subtle nuances in language.
- Knowledge Integration: Large models can integrate and utilize knowledge acquired during pre-training, sometimes exhibiting a degree of common-sense reasoning and problem-solving abilities.
- Adaptability: Although large models learn general knowledge during pre-training, they can be fine-tuned to adapt to specific tasks, showcasing high flexibility and adaptability.
![]()
Technologies Behind Large Models
Current large models are integrated machine learning models capable of processing various types of data. The foundational technologies in these large models aim to understand and generate information across different sensory modalities, enabling tasks such as image description, visual question answering, or cross-modal translation. Here are several key foundational technologies of large models:
Transformer Architecture
Most existing large models are built on the Transformer model (or just the decoder of the Transformer), which captures global dependencies of input data through self-attention mechanisms and can also capture complex relationships between different modality elements. For example, a multimodal Transformer can simultaneously process image pixels and text words, learning their associations through self-attention layers. This allows large models to understand various modalities, such as text and images, and generate long text sequences while maintaining contextual coherence.
Supervised Fine-Tuning
Supervised fine-tuning (SFT) is a traditional fine-tuning method that continues training the pre-trained large model using labeled datasets. Notably, during the training of large models, the SFT phase typically employs high-quality datasets. Additionally, SFT involves adjusting the model’s parameters to enhance its performance on specific tasks. For instance, to improve a model’s performance in legal consulting, a dataset containing legal questions and professional lawyer responses can be used for SFT. During SFT, the model typically attempts to minimize the difference between predicted outputs and true labels, often achieved through loss functions (like cross-entropy loss). This method is direct and straightforward, allowing for rapid adaptation to new tasks. However, it also has limitations, as it relies on high-quality labeled data and may lead to overfitting on the training data.
Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) is a more complex training method that combines elements of supervised learning and reinforcement learning. The model is first pre-trained on a large amount of unlabeled text, similar to the previous SFT step. Then, human evaluators interact with the model or assess its outputs, providing feedback on its performance, and using human feedback data to train a reward model that can predict scores that human evaluators might assign. Finally, the reward model is used as a signal for reinforcement learning to optimize the original model’s parameters. In this process, the model attempts to maximize the expected rewards it receives. The advantage of RLHF is that it helps the model learn more complex behaviors, especially when tasks are difficult to define through simple correct or incorrect labels. Additionally, RLHF can help the model better align with human preferences and values.
![]()
Applications of Large Models
Large models, with their vast parameter counts, deep network structures, and extensive pre-training capabilities, can capture complex data patterns, demonstrating exceptional performance across multiple fields. They can not only understand and generate natural language but also handle complex visual and multimodal information, adapting to various dynamic application scenarios.
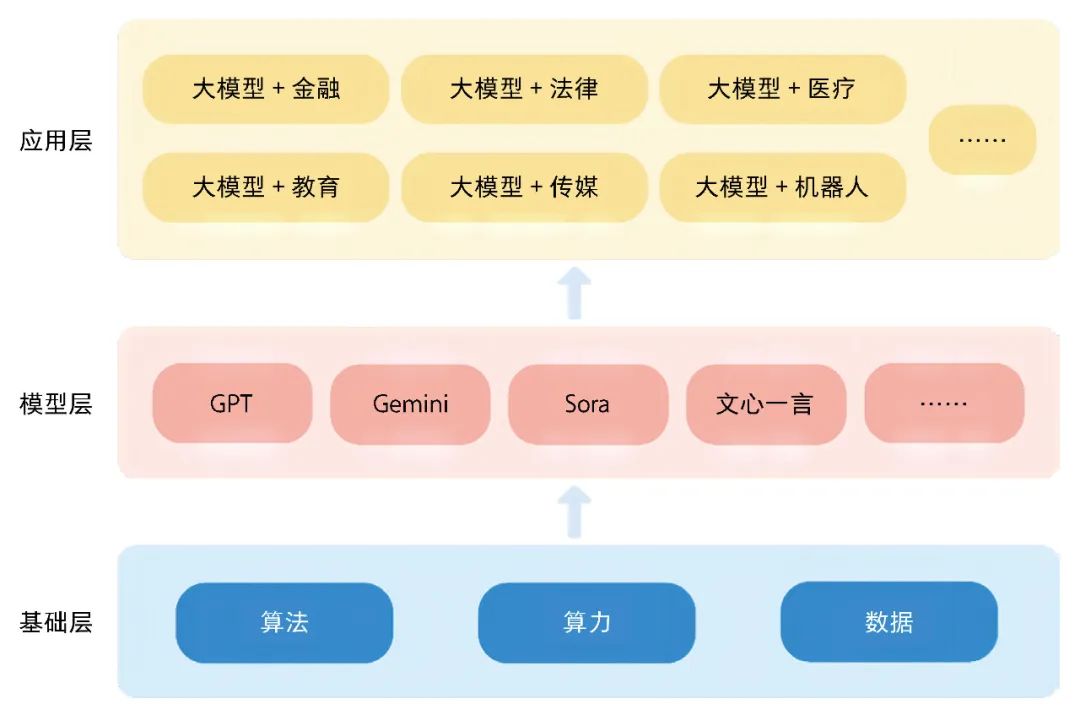
Applications in NLP
Large models have particularly widespread applications in the NLP field. For example, OpenAI’s GPT series models can generate coherent and natural text, used in chatbots, automated writing, and language translation, with ChatGPT being a well-known product. In the fintech sector, large models are often used for risk assessment, trading algorithms, and credit scoring. They can analyze vast amounts of financial data, predict market trends, and assist financial institutions in making better investment decisions. In the legal and compliance fields, they can be used for document review, contract analysis, and case studies. Through NLP technology, models can understand and analyze legal documents, enhancing the efficiency of legal professionals. Recommendation systems are another application area for large models. By serializing user behavior data into text, large models can predict user interests and recommend relevant products, movies, music, etc. In the gaming sector, large models can utilize their coding capabilities to generate complex game environments, driving non-player characters (NPCs) to produce different dialogues based on player settings, providing a more realistic gaming experience.
Applications in Image Understanding and Generation
Currently, large models possess not only text understanding capabilities but also multimodal understanding capabilities, laying the foundation for their applications in the image domain, such as automatic painting and video generation. These models can mimic artists’ styles to create new artistic works, assisting human creativity. For instance, OpenAI’s Sora, released in February 2024, can generate a video segment that meets user input requirements, providing a more convenient tool for film production. In image processing, models like SegGPT are used for image recognition, classification, and generation. They learn from extensive image data paired with text to identify objects, faces, and scenes in images, playing roles in medical image analysis, autonomous vehicles, and video surveillance. Additionally, in the fields of medicine and biology, multimodal large models can be used for disease diagnosis, drug discovery, and gene editing, extracting useful information from complex biomedical data to assist doctors in making more accurate diagnoses or helping researchers design new drugs.
Applications in Speech Recognition
Large models also play a significant role in the field of speech recognition. Through deep learning technologies, models can convert speech into text, supporting applications such as voice assistants, real-time speech transcription, and automatic subtitle generation, with mobile voice assistants being a typical example. These models learn from a vast number of speech samples, enabling them to handle various accents, intonations, and noise interference.
Moreover, large models can be applied across various industries, including education, healthcare, agriculture, and finance. For example, in the education sector, large models can be used for personalized learning, automatic grading, and intelligent tutoring, providing customized teaching content based on students’ learning situations to help them learn more efficiently. In summary, large models demonstrate immense potential across various fields through their powerful data processing and learning capabilities. With continuous technological advancements, it is foreseeable that large models will play an increasingly important role in future developments.
![]()
Development of Large Models
In the current AI landscape, large models have become an undeniable trend. With the continuous advancement of deep learning technologies, particularly in NLP and CV fields, large models are driving breakthroughs in cutting-edge technologies with their powerful data processing and pattern recognition capabilities.
The development of large models at the technical level benefits from several key factors. First is the innovation of algorithms, especially since the introduction of the Transformer architecture, which has rapidly propelled the development of subsequent models, including BERT, the GPT series, and T5. These models achieve leading performance in multiple NLP tasks through pre-training and fine-tuning strategies. Second is the enhancement of computational power, particularly advancements in graphics processing units (GPUs) and tensor processing units (TPUs), enabling the training of models with tens of billions or even hundreds of billions of parameters. Additionally, the rise of cloud computing platforms has provided the necessary computational resources for training large models. At the same time, large-scale datasets have provided ample “nutrition” for model training. These datasets typically contain rich linguistic expressions, scene information, and user interactions, enabling models to capture complex data distributions and linguistic patterns.
The development of large models at the application level has two main directions: large language models and multimodal large models. In the case of large language models, GPT-3 serves as a milestone, reaching 175 billion parameters and showcasing astonishing language understanding and generation abilities. Following closely, Meta AI’s LLaMA series models have become favorites in academic research and industry due to their excellent performance and relatively smaller model sizes. These models not only excel in standard NLP tasks but also exhibit tremendous potential in few-shot learning and transfer learning.
Multimodal large models extend upon this foundation, capable of processing and understanding various types of inputs, such as text, images, and audio. OpenAI’s DALL-E and CLIP are representative works in this direction, capable of understanding and generating images that correspond to text descriptions or understanding text content through images. Google’s SimCLR represents an important exploration in the CV field, effectively extracting image features through contrastive learning. Subsequently, Google’s Gemini has made significant strides in native multimodal capabilities, pre-training across different modalities and handling more complex inputs and outputs, such as images and audio. OpenAI’s Sora further expands the application range of large models, capable of automatically generating video content based on input text, simulating interactions between characters and environments in both the physical and digital worlds.
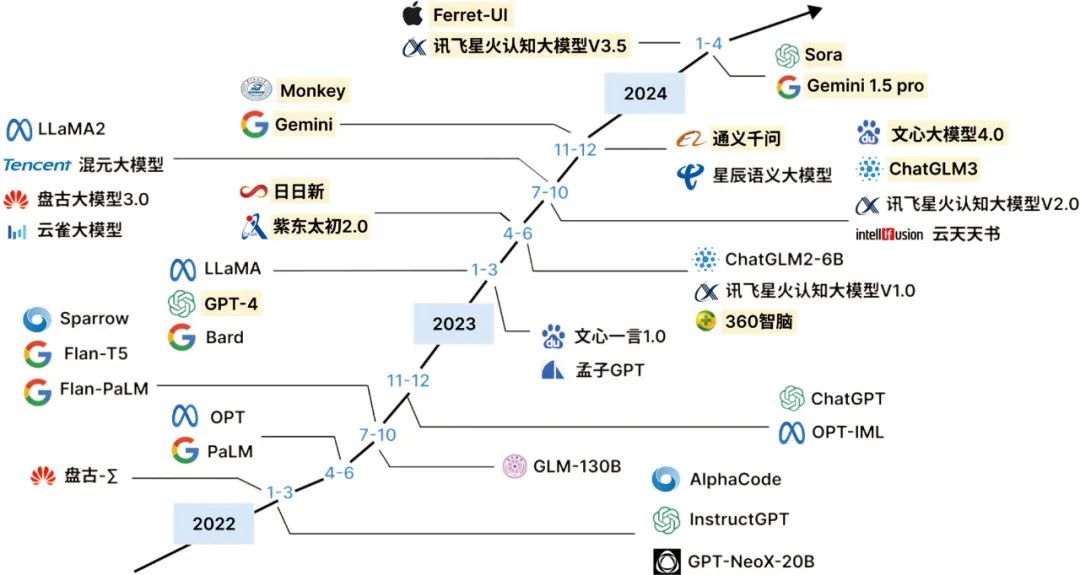
Domestic tech companies are also actively exploring large models. Models such as Baidu’s “Wenxin Yiyan”, Alibaba’s “Tongyi Qianwen”, Huawei’s “Pangu”, and iFLYTEK’s “iFLYTEK Spark” have emerged, demonstrating excellent performance in general language understanding and generation tasks, as well as specialized application capabilities in specific vertical fields like healthcare, law, and tourism. For example, Ctrip’s “Ctrip Wenda” focuses on tourism-related Q&A, NetEase Youdao’s “Ziyue” is applied in education, and JD Health’s “Jingyi Qianxun” aims to provide medical consultation services.
![]()
Challenges of Large Models
In the AI field, large models are becoming a hot topic in both academic research and industry due to their powerful processing capabilities and broad application prospects. However, as these models continue to expand, the issues faced at the research frontier are becoming increasingly complex.
Model Size
The trade-off between model size and data scale has become a significant challenge. Although model performance often improves with an increase in parameter count, this growth in scale brings substantial computational costs and high demands for data quality. Researchers are searching for optimal balances between model size and data scale under limited computational resources, exploring techniques like data augmentation, transfer learning, and model compression to reduce model size without sacrificing performance, striving to minimize the operational costs of large models.
Network Architecture
Innovation in network architecture is equally crucial. Almost all existing large models are based on the Transformer architecture. While the Transformer architecture excels at processing sequential data, its low computational efficiency and poor parameter utilization can lead to wasted computational resources. The limitations of the current Transformer architecture have prompted researchers to design new network architectures aimed at improving efficiency and generalization capabilities through enhanced attention mechanisms, introducing sparsity, and adaptive computation. For instance, the state-space-based model Mamba proposed in December 2023 introduces a selection mechanism that significantly addresses the computational efficiency issues of existing Transformer architectures, potentially becoming the next generation of foundational architectures for large models.
Prompt Engineering
In dealing with imbalanced datasets, prompt learning offers a new paradigm for addressing this issue. By embedding specific prompts in input data, prompt learning can improve model performance on minority classes. However, designing effective prompts and determining the robustness of these prompts (ensuring effectiveness across different types of large models) has become a discipline—prompt engineering. Further research is needed to combine well-designed prompts with other large model technologies.
Contextual Reasoning
As model sizes grow, emergent capabilities such as contextual reasoning have surfaced, indicating that large models may have internalized cognitive and learning mechanisms closer to human understanding. The nature, triggering conditions, and controllability of these emergent capabilities are current research hotspots, requiring further exploration from cognitive science and neuroscience perspectives to provide more reasonable explanations and help people understand the principles behind the emergence of these abilities.
Knowledge Updating
The continuous updating of knowledge is another critical issue faced by large models. As knowledge progresses, the information within models can quickly become outdated. Researchers are exploring ways to enable models to learn continuously and integrate new knowledge while avoiding catastrophic forgetting, keeping the model’s knowledge base up to date.
Explainability
Despite their outstanding performance in various NLP and machine learning tasks, as the parameter count and network structure of models deepen, the decision-making processes of models become increasingly difficult to explain. The black-box nature of large models makes it challenging for users to understand how models process input data and generate output results. This leads to a passive understanding state, where people only know the model’s output but are unaware of why the model made such decisions.
Privacy and Security
The training data of large models may encompass personal identity information, sensitive data, or trade secrets. If these data are not adequately protected, the training process of the model may pose risks of privacy breaches or misuse. Additionally, large models themselves may contain sensitive information, such as memories gained from training on sensitive data, making the models inherently prone to privacy risks.
Data Bias and Misleading Information
Large language models may output biased or misleading content, stemming from various factors such as data collection methods, annotators’ subjective preferences, and social culture. When models are trained on biased data, they may incorrectly learn or amplify these biases, leading to unfair or discriminatory outcomes in practical applications.
Addressing these issues is crucial for advancing large model technology and expanding its application scope. Solving each challenge could promote more effective applications of AI in the real world, bringing profound impacts to human society.
![]()
Future of Large Models
As AI technology continues to evolve and the application scenarios for large model technology expand, the future trends of large models are also presenting new characteristics and development directions.
Balancing Model Scale and Efficiency
Since large model technology often requires substantial computational resources and storage space, future development trends will focus on maintaining model scale while improving efficiency to meet practical application needs. Currently, sparse expert models are gaining attention as a novel architectural approach. Compared to traditional dense models, sparse expert models reduce computational demands by activating only the model parameters relevant to the input data, thereby enhancing computational efficiency. Google’s sparse expert model GlaM, developed in 2023, has seven times more parameters than GPT-3 but reduces energy consumption during training and the computational resources required for inference, outperforming traditional models in various NLP tasks.
Deep Integration of Knowledge
Knowledge integration aims to enrich the model’s representational and decision-making capabilities by combining information from different data sources and knowledge domains. Currently, large models primarily train and apply to single-domain or single-modality data, such as BERT in the NLP domain and ViT in the CV domain. However, in the real world, text, images, audio, and other types of information are often interrelated, making it difficult for single-modality information to meet the demands of complex scenarios. Therefore, with the continuous development of CV, speech recognition, and other technologies, future large models will place greater emphasis on multimodal integration, processing data from different modalities to achieve the fusion and interaction of multimodal information. This capability for multimodal integration allows large models to better understand and process complex information. Moreover, it may be beneficial to combine large model technology with external knowledge bases to further enhance the model’s understanding and application breadth. This means that models can leverage not only their internal language patterns and statistical information but also integrate external structured knowledge for reasoning and decision-making, better addressing complex issues in the real world. Importantly, external knowledge can also enhance the generalization capabilities of large models.
Exploration of Embodied Intelligence
Embodied intelligence refers to intelligent systems that perceive and act based on a physical body, acquiring information, understanding problems, making decisions, and executing actions through interactions with the environment. The proliferation of large models has significantly accelerated the research and implementation of embodied intelligence. Large language models are becoming key tools to help robots better understand and utilize advanced semantic knowledge. By automating task analysis and breaking them down into specific actions, large model technology makes interactions between robots and humans, as well as physical environments, more natural, enhancing the intelligent performance of robots. For instance, different tasks can be achieved through different large models. By using language large models for learning dialogue, visual large models for map recognition, and multimodal large models for executing physical actions, robots can learn concepts more efficiently and direct actions, while decomposing all instructions for execution, completing automated scheduling and collaboration through large model technology. This comprehensive utilization of different models presents new opportunities and challenges for the intelligent development of robots.
Explainability and Trustworthiness
As model scales increase, their internal structures become increasingly complex, making the explainability and trustworthiness of models focal points of concern. First, to enhance model explainability, researchers will focus on developing new methods and technologies that enable large models to clearly explain their decision-making processes and the basis for their generated results. This may involve introducing more transparent model structures, such as transparent neural networks or interpretable attention mechanisms, and developing explanatory algorithms and tools to help users understand model outputs.
Secondly, to enhance model trustworthiness, a series of measures will be taken to reduce the likelihood of models producing errors or misleading information. One important direction is to introduce external information sources and provide models with the capability to access and reference these sources. This way, models will be able to access the most accurate and up-to-date information, thereby improving the accuracy and trustworthiness of their output results.
At the same time, to increase transparency and trust, models will also provide citations related to external information sources, allowing users to audit these sources to determine their reliability. Notably, while some large models with external information access and citation capabilities have already emerged, such as Google’s REALM and Facebook’s RAG, this is merely the beginning of development in this field. In the future, more innovations and advancements are expected, with new models like OpenAI’s WebGPT and DeepMind’s Sparrow further propelling development in this area, laying a more solid foundation for the future applications of large model technology. The future development of large model technology will increasingly emphasize explainability and trustworthiness, which is not only an inevitable trend in technological development but also a reasonable requirement from society for the application of technology. Only by continuously enhancing the explainability and trustworthiness of models can large model technology be better applied across various fields, bringing greater impetus to the development of human society.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.