Last week, while sharing my article on “My Transition Journey as an AI Product Manager,” I hinted that I would produce a comprehensive article to help everyone systematically learn about large models. Today, I am delivering that article; it totals 22,000 words, and reading it is expected to take about 30 minutes, covering 15 topics related to large models.

Over the past year, to be honest, there have been numerous articles introducing and explaining large models. Most people already have some foundational understanding, but my feeling is that the information is too fragmented and does not provide a systematic understanding. Currently, there is no article that can comprehensively explain what large models are in one go.
To alleviate my cognitive anxiety, I decided to compile the knowledge points I have understood about large models over the past year into one article, hoping to clarify large models through a single piece of writing. This also serves as a summary of my extensive learning.
What Will I Share?
This article will share 15 topics related to large models. Initially, there were 20 topics, but I removed some more technical content to focus on issues that ordinary people or product managers should pay attention to. The goal is to ensure that as AI novices, we only need to master and understand these key points.
Who Is This Article For?
This article is suitable for the following groups:
- Those who want to understand what large models are all about, including beginners.
- Those looking to transition into AI-related products and roles, including product managers and operations personnel.
- Those who have a preliminary understanding of AI but wish to advance their learning and reduce cognitive anxiety about AI.
Content Statement: The entire content is a result of my personal synthesis after extensive reading and digesting numerous expert articles, books related to large models, and consultations with industry experts. My role is mainly as a knowledge synthesizer. If there are any inaccuracies in the descriptions, please feel free to inform me kindly!
Lecture 1: Common Concepts of Large Models
Before we start understanding large models, let’s first grasp some basic concepts. Mastering these professional terms and their relationships will benefit your subsequent reading and learning about any AI and large model-related content. I spent quite a bit of time organizing their relationships, so this part is essential to read carefully.
1. Common AI Terms
1) Large Model (LLM): All existing large models refer to large language models, specifically generative large models. Examples include GPT-4.0, GPT-4o, etc.
- Deep Learning: A subfield of machine learning focused on using multi-layer neural networks for learning. Deep learning is effective in handling complex data such as images, audio, and text, making it very effective in AI applications.
- Supervised Learning: A method of machine learning where the model learns the mapping from input to output using a labeled training dataset. Common supervised learning algorithms include linear regression, logistic regression, support vector machines, K-nearest neighbors, decision trees, and random forests.
- Unsupervised Learning: A method of machine learning that finds patterns and structures in data without labeled data. It is mainly used for clustering and dimensionality reduction tasks. Common unsupervised learning algorithms include K-means clustering, hierarchical clustering, DBSCAN, principal component analysis (PCA), and t-SNE.
- Semi-supervised Learning: Combines a small amount of labeled data with a large amount of unlabeled data for training. It utilizes the rich information from unlabeled data and the accuracy of labeled data to improve model performance. Common methods include Generative Adversarial Networks (GANs) and autoencoders.
- Reinforcement Learning: A method of learning optimal strategies through interaction with the environment based on reward and punishment mechanisms. Reinforcement learning algorithms optimize decision-making processes through trial and error to maximize cumulative rewards. Common algorithms include Q-learning, policy gradient, and Deep Q-Networks (DQN).
- Model Architecture: Represents the design of the backbone of a large model. Different model architectures affect the performance, efficiency, and even computational costs of large models, determining their scalability. For example, many large model vendors adjust the model architecture to reduce computational load and resource consumption.
- Transformer Architecture: The mainstream architecture used by current large models, including GPT-4.0 and most domestic large models. The widespread use of the Transformer architecture is primarily due to its ability to enable large models to understand human natural language, maintain contextual memory, and generate text. Other common model architectures include Convolutional Neural Networks (CNNs) for image processing and Generative Adversarial Networks (GANs) for image generation. A detailed introduction to the Transformer architecture will be covered later.
- MOE Architecture: Represents the Mixture of Experts architecture, which combines multiple expert models to form a large model with a vast number of parameters, supporting the resolution of various complex professional problems. Models with MOE architecture may include Transformer-based models.
- Machine Learning Technologies: A broad category of technologies that implement AI, including deep learning, supervised learning, and reinforcement learning. As a product manager, you don’t need to delve too deeply into the specifics; just understand the relationships between these learning types to avoid being misled by technical personnel.
- NLP Technology (Natural Language Processing): An application area of AI focused on enabling computers to understand, interpret, and generate human language, used in text analysis, machine translation, speech recognition, and dialogue systems. In simpler terms, it is a technology that converts a lot of information into a format understandable by human natural language.
- CV Technology (Computer Vision): If NLP deals with text, CV addresses visual content-related technologies. CV technologies include common image recognition, video analysis, and image segmentation technologies, which are also prevalent in large model applications, especially in the upcoming multi-modal large model technologies.
- Speech Recognition and Synthesis Technologies: Includes converting speech to text and speech synthesis technologies, such as Text-to-Speech (TTS) technology.
- Retrieval-Augmented Generation (RAG): Refers to the technology where large models generate content based on information retrieved from search engines and knowledge bases. RAG is a technology involved in most AI applications.
- Knowledge Graph: A technology that connects knowledge, allowing knowledge to establish relationships, helping models acquire the most relevant knowledge more effectively and enhancing their ability to process complex relational information and AI reasoning.
- Function Call: Refers to the ability in large language models (like GPT) to call built-in or external functions to perform specific tasks or operations. This mechanism allows the model to be more than just a text generation tool, enabling it to execute a variety of operations by specifying different functionalities. Function Call allows large models to integrate with various API capabilities, enhancing their practical applications, such as supporting content retrieval and document recognition.
2) Terms Related to Large Model Training and Optimization Technologies
- Pre-training: Refers to the process of training a model on a large dataset. The pre-training dataset is usually large and diverse, resulting in a general-purpose model with strong capabilities, similar to a person who has learned various general knowledge through compulsory education and university studies.
- Fine-tuning: Refers to further training a large model on specific tasks or smaller datasets to improve its performance on targeted problems. Unlike the pre-training phase, the fine-tuning phase uses a smaller amount of data, primarily from vertical domains. The fine-tuning process results in a specialized or industry-specific model, akin to a new graduate receiving professional skill training after joining a company.
- Prompt Engineering: In product manager terms, this means using question formats that large models can better understand to yield the desired results. Therefore, prompt engineering is a skill in learning how to ask questions effectively.
- Model Distillation: A technique that transfers knowledge from a large model (the teacher model) to a smaller model (the student model). The student model learns from the outputs of the teacher model to improve its performance while maintaining similar accuracy.
- Model Pruning: Refers to the removal of unnecessary parameters from a large model to reduce its overall parameter size, thereby lowering computational load and cost.
3) AI Application-Related Terms
- Agent: An agent is simply understood as an AI application with a specific capability. If applications in the internet era are called apps, applications in the AI era are called agents.
- Chatbot: Refers to AI chatbots, a type of AI application that interacts through chat, including products like ChatGPT, which belong to the chatbot category.
4) Terms Related to Large Model Performance
- Emergence: Refers to the phenomenon where large models exhibit capabilities beyond expectations once their parameter scale reaches a certain level.
- Hallucination: Refers to instances where large models generate nonsensical content, mistakenly treating incorrect facts as real, leading to unrealistic outputs.
- Amnesia: Refers to the situation where, after a certain number of dialogue turns and length, the model suddenly forgets and begins to repeat itself and forgets previous context. The memory of large models is mainly influenced by factors like the model’s context length.
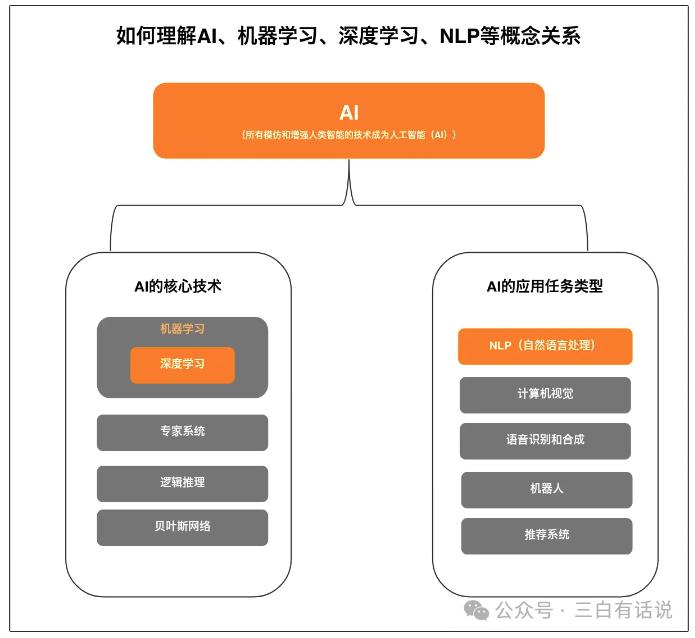
2. Understanding the Relationship Between AI, Machine Learning, Deep Learning, and NLP
If you are interested in AI and large models, you will likely encounter keywords like “AI,” “Machine Learning,” “Deep Learning,” and “NLP” in your future studies. Therefore, it is best to clarify the concepts and definitions of these professional terms and their logical relationships for easier understanding.
In summary, the relationship between these concepts is as follows:
- Machine learning is a core technology of AI. Besides machine learning, AI’s core technologies include expert systems, Bayesian networks, etc. (you don’t need to delve too deeply into what these are), with deep learning being a type of machine learning.
- NLP is one of the application task types in AI, focused on natural language processing. Besides NLP, AI application technologies also include CV (computer vision) technology, speech recognition and synthesis technologies, etc.
3. Understanding the Transformer Architecture
When discussing large models, one cannot overlook the Transformer architecture. If large models are like a tree, the Transformer architecture serves as the trunk of the model. The emergence of products like ChatGPT is primarily due to the design of the Transformer architecture, which enables models to understand context, maintain memory, and predict unknown words. Additionally, the introduction of the Transformer has allowed large models to train on unlabeled data without relying heavily on large amounts of labeled data. This breakthrough means that previously, creating a model required significant human effort for data cleaning and labeling, but now, fragmented and scattered data can simply be fed into the model for processing. We can understand these concepts through the following points:
Relationship Between Transformer Architecture and Deep Learning Technologies: The Transformer architecture belongs to the category of deep learning technologies, meaning it is an implementation and design form within deep learning. Besides the Transformer architecture, traditional Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) are also part of deep learning.
4. Understanding the Relationship Between the Transformer Architecture and GPT
GPT stands for Generative Pre-trained Transformer, meaning GPT is a large language model developed based on the Transformer architecture by OpenAI.
The core idea of GPT is to enhance the ability to generate and understand natural language through large-scale pre-training and fine-tuning. The emergence of the Transformer architecture has solved the issues of understanding context, processing large amounts of data, and predicting text. However, OpenAI was the first to adopt the pre-training + fine-tuning approach to improve and utilize the Transformer architecture, enabling it to possess the capabilities of products like ChatGPT for understanding and generating natural language.
The reason GPT can generate and understand natural language is that during the pre-training phase, it learns broad language patterns and knowledge from a large corpus of unlabeled text, with the pre-training task typically being a language modeling task, where the model predicts the next word given a sequence of preceding words. The specific differences are as follows:
1) Differences in Capabilities: The Transformer architecture enables models to understand context, process large amounts of data, and predict text, but it does not possess the ability to understand and generate natural language. In contrast, GPT, after adding natural language pre-training, has the ability to understand and generate natural language.
2) Architectural Foundations:
- Transformer: The original Transformer model consists of an encoder and a decoder. The encoder processes the input sequence to generate intermediate representations, which the decoder uses to generate the output sequence. This architecture is particularly suitable for sequence-to-sequence tasks, such as machine translation. The encoder employs a bidirectional processing mechanism, allowing it to use bidirectional attention, meaning each word can consider the information from all other words in the sequence, regardless of whether they are preceding or following words.
- GPT: GPT primarily uses the decoder part of the Transformer, focusing solely on generation tasks. Its training and generation processes are unidirectional, meaning each word can only see the preceding words (unidirectional attention). This architecture is more suitable for text generation tasks. The encoder adopts a unidirectional processing mechanism, meaning that when generating the next word, GPT can only consider the previous words, which aligns with the natural form of language modeling.
3) Implementation Methods for Solving Specific Problems:
- The Transformer is trained to solve specific task types (like machine translation) by optimizing its performance through training, with both the encoder and decoder trained simultaneously.
- In contrast, GPT solves specific task types through supervised fine-tuning, meaning it does not require training for specific task types but only needs to provide some specific task data to achieve results. It is important to understand that training and fine-tuning are different implementation cost methods.
4) Application Domains:
- The traditional Transformer framework can be applied to various sequence-to-sequence tasks, such as machine translation, text summarization, and speech recognition. Since it includes both an encoder and a decoder, the Transformer can handle various input and output format tasks.
- GPT is primarily used for generation tasks, such as text generation, dialogue systems, and question-answering systems. It excels in generating coherent and creative text.
5. Understanding the MOE Architecture
In addition to the Transformer architecture, another popular architecture is the MOE architecture (Mixture of Experts), which dynamically selects and combines multiple sub-models (i.e., experts) to complete tasks. The key idea of MOE is to solve a series of complex tasks by combining multiple expert models rather than relying on a single large model for all tasks.
The main advantage of the MOE architecture is its ability to maintain computational efficiency while handling large-scale data and model parameters, significantly reducing computational costs while retaining model capabilities.
The Transformer and MOE can be used in conjunction, commonly referred to as MOE-Transformer or Sparse Mixture of Experts Transformer. In this architecture:
- The Transformer processes input data, leveraging its powerful self-attention mechanism to capture dependencies within the sequence.
- The MOE dynamically selects and combines different experts, enhancing the model’s computational efficiency and capabilities.
Lecture 2: Differences Between Large Models and Traditional Models
When we talk about large models, we typically refer to LLMs (Large Language Models), or more specifically, models like GPT (generative pre-trained models based on the Transformer architecture). Firstly, it is a language model addressing natural language tasks rather than problems in images, videos, or speech. (Models that handle multiple modalities, including language, images, videos, and speech, are later referred to as multi-modal large models, which are not the same concept as LLMs.) Secondly, LLMs are generative models, meaning their primary ability is to generate rather than predict or make decisions.
In contrast to traditional models, large models generally have the following characteristics:
- Ability to Understand and Generate Natural Language: Many traditional models we have encountered may not understand human natural language, let alone generate language that humans can comprehend.
- Powerful and Versatile Capabilities: Traditional models typically solve one or a few problems, with a strong specialization, while large models possess strong general capabilities and can address a wide range of issues.
- Contextual Memory Capabilities: Large models have memory capabilities, allowing them to relate to contextual dialogues rather than being forgetful robots, which is one of the key differences from many traditional models.
- Training Method: Based on large amounts of unlabeled text, pre-training is conducted through unsupervised methods. Unlike many traditional models that rely on large amounts of labeled data, the unsupervised approach significantly reduces the costs of data cleaning and preparation. Furthermore, pre-training requires a massive amount of training data; for example, GPT-3.5’s training corpus reached 45 terabytes.
- Massive Parameter Scale: Most large models have parameter scales in the hundreds of billions, such as GPT-3.5, which has 175 billion parameters, while GPT-4.0 is rumored to reach trillions of parameters. These parameters learn and adjust during the model training process to perform specific tasks better.
- Training Requires Significant Computational Resources: Due to their scale and complexity, these models require substantial computational resources for training and inference, typically needing specialized hardware like GPUs or TPUs. Research indicates that training generative AIs like ChatGPT requires support from at least 10,000 NVIDIA A100 accelerator cards, with training costs for models like GPT-3.5 reaching up to $9 million.
Lecture 3: Evolution of Large Models
1. Evolution of Large Model Generation Capabilities
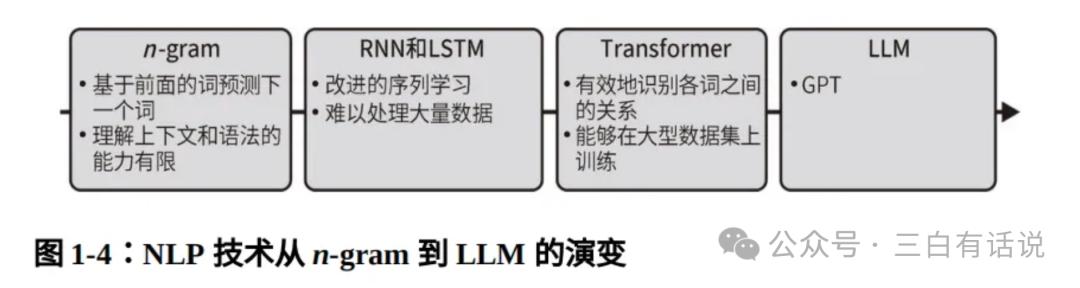
Understanding the evolution of LLMs helps everyone grasp how large models have gradually acquired their current capabilities and makes it easier to understand the relationship between LLMs and Transformers. The following outlines the evolution of large models:
- N-gram: The earliest stage of large model generation capabilities, primarily addressing the ability to predict the next word. This forms the basis of text generation, but its limitations lie in understanding context and grammatical structures.
- RNN (Recurrent Neural Network) and LSTM (Long Short-Term Memory): At this stage, these two models addressed the issue of context length, enabling relatively longer context windows, but they struggled to handle large amounts of data.
- Transformer: Combines the predictive capabilities of the previous two models with the ability to remember longer contexts while supporting training on large datasets, but lacks the ability to understand and generate natural language.
- LLM (Large Language Model): Adopts the GPT pre-training and supervised fine-tuning approach, enabling the model to understand and generate natural language, thus called a large language model. It can be said that the emergence of pre-training and supervised fine-tuning brought the Transformer into the development stage of large models.
2. Development History from GPT-1 to GPT-4
GPT-1: Introduced the unsupervised training step for the first time, solving the problem of needing large amounts of labeled data for previous models. The unsupervised training method allows GPT to train on a vast amount of unlabeled data. However, its limitations stem from the small parameter scale (only 117 million parameters), making it unable to solve complex tasks without supervised fine-tuning, which can be cumbersome.
GPT-2: Increased the parameter scale to 1.5 billion and expanded the training text size fourfold to 40GB. By increasing parameter scale and training data size, the model’s capabilities improved, but it still faced limitations in addressing complex problems.
GPT-3: Expanded the parameter scale to 175 billion, achieving remarkable performance in text generation and language understanding, and eliminated the fine-tuning step, meaning it could solve complex problems without needing fine-tuning. However, GPT-3’s limitations arose from its training on a vast amount of internet data, which may include false and erroneous texts, leading to safety issues.
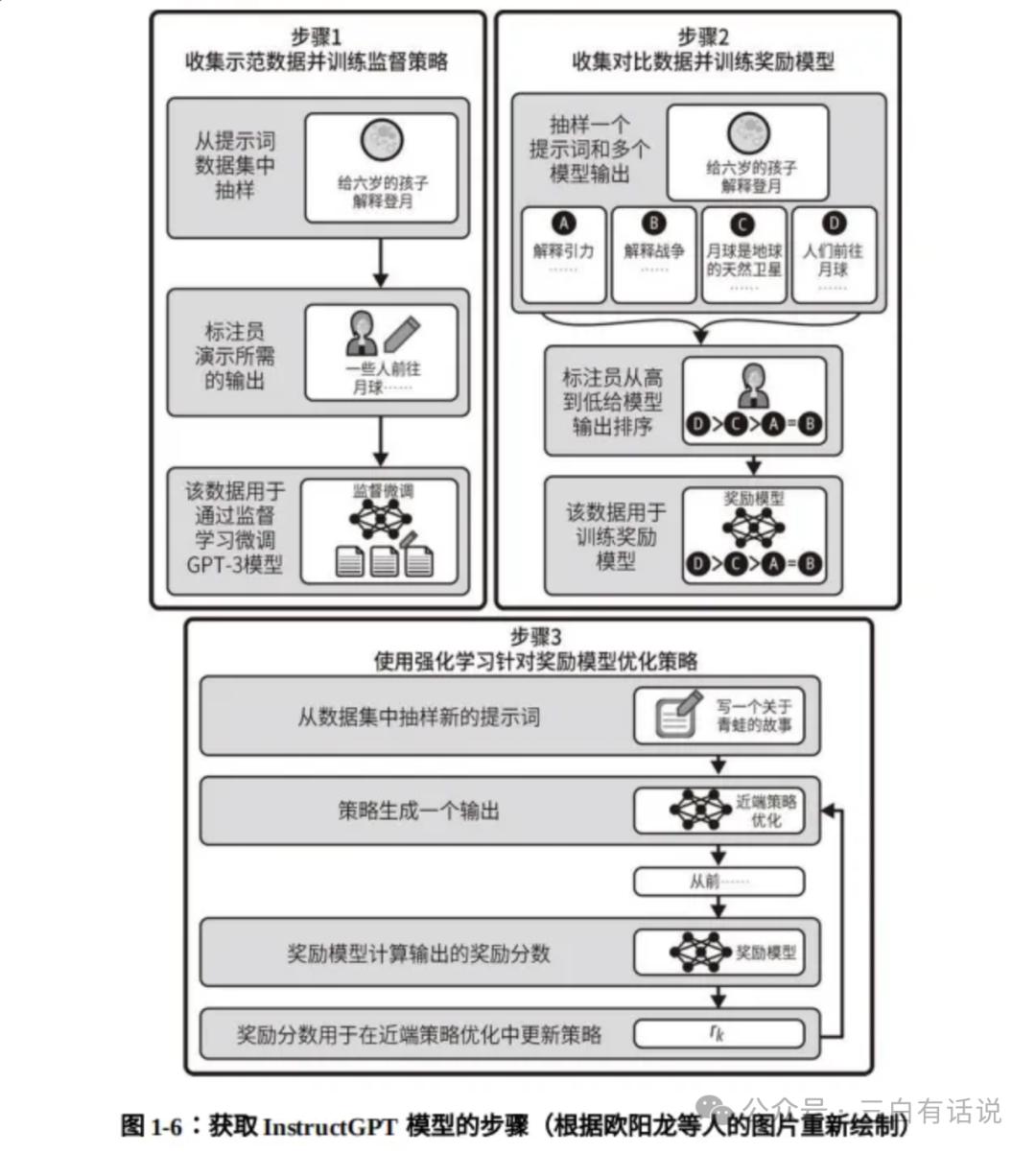
InstructGPT: To address the limitations of GPT-3, supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) were added after pre-training to optimize the model’s errors. This model became InstructGPT. The process involves providing the model with some real “standard answers” for supervised fine-tuning, constructing a scoring model for the generated results, and using the scoring model to adjust the model’s strategy for improvement. Thus, many large model vendors focus on the quality and quantity of data provided during the supervised fine-tuning stage to reduce hallucination rates.
GPT-3.5: Released in March 2022, OpenAI’s GPT-3 new version had a training data cutoff in June 2021, with an expanded training data size of 45TB, and was referred to as GPT-3.5 in November.
GPT-4.0: Released in April 2023, OpenAI significantly improved overall reasoning capabilities and supported multi-modal capabilities.
GPT-4o: Released in May 2024, enhanced voice chat capabilities.
O1: In September 2024, OpenAI launched the O1 model, focusing on enhancing reasoning capabilities.
3. Principles of Text Generation in Large Models
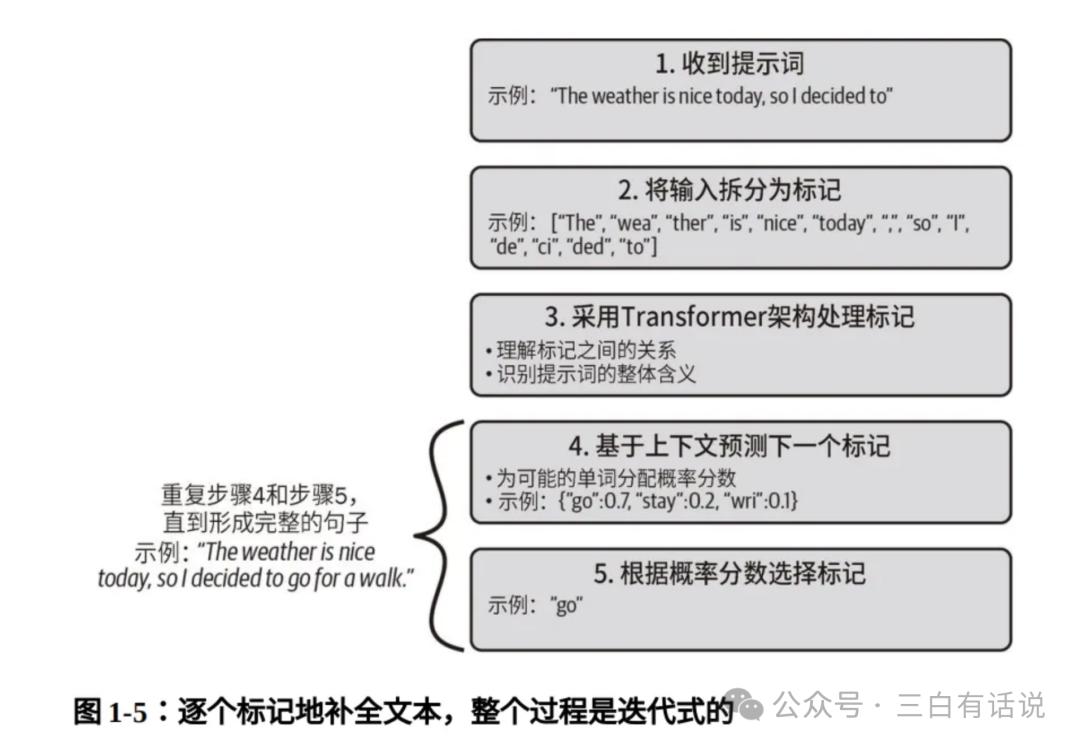
1. How Does GPT Generate Text?
The process of a large model generating text can be summarized in five steps:
- After receiving a prompt, the model first tokenizes the input content, breaking it into multiple tokens.
- Based on the Transformer architecture, it understands the relationships between tokens to grasp the overall meaning of the prompt.
- It predicts the next token based on context, which may yield multiple results, each with corresponding probability values.
- The token with the highest probability is selected as the predicted result for the next word.
- The fourth step is repeated until the entire content is generated.
2. Classification of LLMs
1. Classification by Modality Type
Currently, large models on the market can be categorized into text generation models (e.g., GPT-3.5), image generation models (e.g., DALL-E), video generation models (e.g., Sora, 可灵), speech generation models, and multi-modal models (e.g., GPT-4.0).
2. Classification by Training Stage
Models can be divided into basic language models and instruction fine-tuned models:
- Basic Language Model: Refers to models that have only undergone pre-training on large-scale text corpora without any instruction or downstream task fine-tuning, such as GPT-3, which is the publicly available basic language model from OpenAI.
- Instruction Fine-tuned Model: Refers to models that have undergone instruction fine-tuning, human feedback, and alignment optimizations based on natural language task descriptions. For example, GPT-3.5 is trained based on GPT-3.
3. Classification by General and Industry Models
Large models on the market can also be classified into general large models and industry-specific models. General large models perform well across a wide range of tasks and fields, but may not fully understand and utilize domain-specific information, thus may not solve specific industry or scenario problems. Industry-specific models, on the other hand, are trained and adjusted based on general large models to achieve higher performance and accuracy in specific fields.
3. Core Technologies of LLMs
This section may contain many technical terms that are relatively difficult to understand. However, for product managers, it is not necessary to delve into the technical details; understanding the key concepts is sufficient. It is essential for AI product managers to comprehend technical terms to facilitate communication with development and technical teams.
1. Model Architecture: The Transformer architecture has been described in detail earlier, so I will not repeat it here. However, the Transformer architecture is one of the foundational core technologies of large models.
2. Pre-training and Fine-tuning
- Pre-training: Conducted on large-scale unlabeled data, this is one of the key technologies for large language models. The emergence of pre-training technology means that models no longer need to rely on large amounts of labeled data, significantly reducing the costs of manual labeling.
- Fine-tuning: This technology is used to further leverage large models. The performance of pre-trained models on specific tasks is generally average, so fine-tuning on specific datasets is needed to adapt to specific applications. Fine-tuning can significantly enhance model performance on specific tasks.
3. Model Compression and Acceleration
- Model Pruning: By removing unimportant parameters, the size of the model and computational complexity can be reduced.
- Knowledge Distillation: Training a smaller student model to mimic the behavior of a large teacher model, retaining most performance while reducing computational costs.
Lecture 7: Six Steps in Large Model Development
According to information released by OpenAI, the development of large models typically goes through the following six steps. This process should be representative of the development process for most large models in the industry:
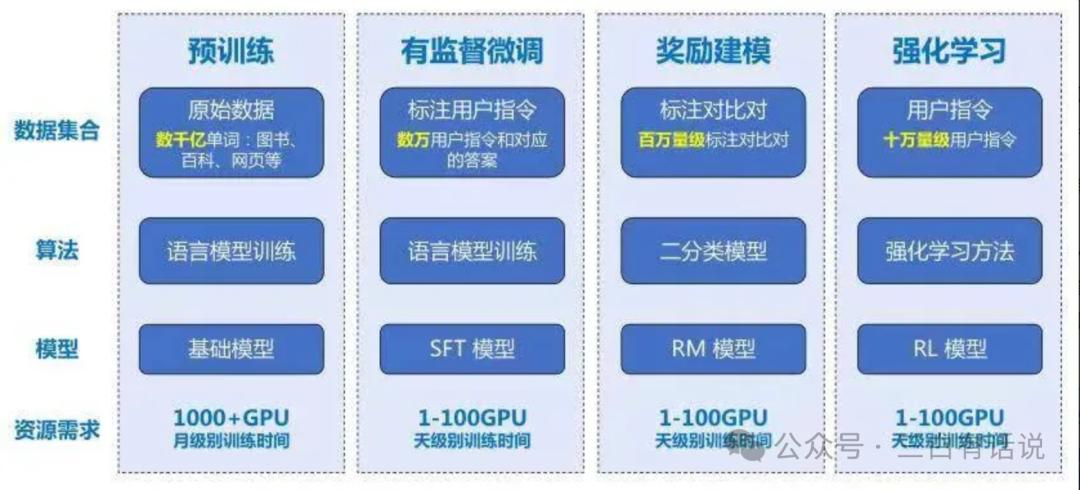
- Data Collection and Processing: This stage involves collecting a large amount of text data, which may include books, web pages, articles, etc. The data is then cleaned to remove irrelevant or low-quality content, followed by preprocessing such as tokenization and removal of sensitive information.
- Model Design: Determining the model architecture, such as the Transformer architecture used by GPT-4, and setting the model size, including the number of layers, hidden units, and total parameters.
- Pre-training: At this stage, the model acts like a student in school, learning language and knowledge by reading a large number of books (such as web pages and articles). Or, it can be likened to a “sponge” absorbing as much information as possible, learning basic language rules, such as how to form sentences and how words relate to each other. At this point, the model can understand basic language structures but lacks specialized knowledge for specific tasks. The pre-training phase typically requires a very large amount of data, consuming the most computational resources and time; for example, completing one pre-training session for GPT-3 requires 3640 petaflops of computation and nearly 1,000 GPUs.
- Instruction Fine-tuning: Also known as supervised fine-tuning, this process involves feeding the model some question-answer pairs with ideal outputs for further training, resulting in a supervised fine-tuned model. This stage is akin to “career training,” where the model learns how to adjust its responses based on specific instructions or tasks, improving its performance on specific types of questions or tasks. The instruction fine-tuning stage requires relatively fewer high-quality data, making the training time and consumption smaller.
- Reward: This stage sets up an “incentive mechanism” for the model, teaching it what constitutes a good response or behavior through rewards. This approach helps the model better meet user needs and focus on providing valuable, accurate answers. This process requires the model’s trainers to extensively evaluate and provide feedback on the model’s responses, gradually adjusting the quality of its responses, which also requires relatively high-quality data and takes days to complete.
- Reinforcement Learning: In this final stage, the model undergoes “live drills,” learning how to improve through trial and error. During this phase, the model attempts various strategies in real-world complex situations, identifying the most effective methods. The model becomes smarter and more flexible during this stage, enabling it to make better judgments and responses in complex and uncertain situations.
Lecture 8: Understanding Large Model Training and Fine-tuning
1. Understanding Large Model Training Content
1) What Data Is Needed for Large Model Training?
- Text Data: Mainly used for training language models, such as news articles, books, social media posts, Wikipedia, etc.
- Structured Data: Such as knowledge graphs, used to enhance the language model’s knowledge.
- Semi-structured Data: Such as XML and JSON formats, which facilitate information extraction.
2) Sources of Training Data
- Public Datasets: Such as Common Crawl, Wikipedia, OpenWebText, etc.
- Proprietary Data: Company internal data or paid proprietary data.
- User-Generated Content: Content generated by users on social media, forums, comments, etc.
- Synthetic Data: Data generated through Generative Adversarial Networks (GANs) or other generative models.
3) What Are the Costs of Large Model Training?
- Computational Resources: The cost of using GPUs/TPUs depends mainly on the model’s scale and training time. Large models typically require thousands to tens of thousands of hours of GPU computing time.
- Storage Costs: For storing large-scale datasets and model weights. Datasets and model files can reach terabyte levels.
- Data Acquisition Costs: The cost of purchasing proprietary data or the labor costs for data cleaning and labeling.
- Energy Costs: Training large models consumes a significant amount of electricity, increasing operational costs.
- R&D Costs: Including salaries for researchers and engineers, as well as the costs of developing and maintaining models.
2. Understanding Large Model Fine-tuning Content
- Two Stages of Large Model Fine-tuning: Supervised Fine-tuning (SFT) and Reinforcement Learning (RLHF). The differences between the two stages are as follows:

2) Two Methods of Large Model Fine-tuning: Lora Fine-tuning and SFT Fine-tuning
Currently, there are two methods for fine-tuning models: Lora fine-tuning and SFT fine-tuning. The differences between these two methods are:
- Lora fine-tuning adjusts only a portion of the model’s parameters, not requiring fine-tuning of the entire model. This method is suitable for resource-limited scenarios or targeted fine-tuning, allowing the model to address single-task scenarios.
- SFT fine-tuning involves adjusting all parameters of the model, fine-tuning the entire model to enable it to address more specific tasks.
Lecture 9: Main Factors Affecting Large Model Performance
As we know, although there are many large models available on the market, there are differences in performance among them. For example, OpenAI’s models hold a leading position in the industry. Why do performance differences exist among large models? The five most important factors affecting large model performance are as follows:
- Model Architecture: The design of the model, including the number of layers, the number of hidden units, and the total number of parameters, significantly impacts its ability to handle complex tasks.
- Quality and Quantity of Training Data: The performance of the model heavily relies on the coverage and diversity of its training data. High-quality and diverse datasets help the model understand and generate language more accurately. Currently, most models mainly use public data, and companies with richer, high-quality data resources will have a competitive advantage. In China, a disadvantage is that open-source datasets are primarily in English, with relatively fewer Chinese datasets.
- Parameter Scale: The more parameters a model has, the better it can learn and capture complex data patterns, but this also increases computational costs. Therefore, companies with strong computational resources will have a higher advantage. The core factors for computational power depend on the computational volume (number of GPUs), network, and storage dimensions.
- Algorithm Efficiency: The algorithms used for training and optimizing the model, such as optimizer selection and learning rate adjustments, significantly impact the model’s learning efficiency and final performance.
- Training Frequency: Ensuring that the model undergoes sufficient training iterations to achieve optimal performance while avoiding overfitting issues.
Lecture 10: How to Measure the Quality of Large Models?
From the application perspective of large models, how to measure the quality of a large model and what evaluation framework to use is essential. Through this section, you can understand the dimensions from which evaluation institutions assess the capabilities of large models. Moreover, if you face selection issues regarding large models, you should establish your own judgment system.
After reading and referencing multiple documents on measuring large models, I have summarized the evaluation dimensions into three aspects:
1. How to Measure the Product Performance of Large Models
Typically, the product performance of a large model is evaluated based on the following dimensions:
1) Semantic Understanding Ability: This includes the basic dimensions of semantics, grammar, and context, which essentially determine whether you can have a normal conversation with the model and whether the model’s responses are coherent, especially regarding Chinese semantic understanding. Furthermore, it also assesses whether the model supports multi-language understanding.
2) Logical Reasoning: This includes the model’s reasoning ability, numerical calculation ability, and contextual understanding ability, which is one of the core capabilities of large models, directly determining the model’s intelligence level.
3) Accuracy of Generated Content: This includes the rate of hallucinations and the ability to identify traps.
4) Hallucination Rate: This includes the accuracy of the model’s responses and results. Sometimes, the model may generate nonsensical content that users may mistakenly believe to be true, which can be quite problematic.
5) Trap Information Identification Rate: This indirectly assesses the model’s ability to recognize and handle trap information, as models that poorly identify traps may generate responses based on incorrect information.
6) Quality of Generated Content: While ensuring the authenticity and accuracy of generated content, the dimensions for measuring content quality include:
- Diversity of Generated Content: Whether the model can support diverse and multi-faceted content outputs.
- Professionalism: Whether the model can produce professional content in vertical scenarios.
- Creativity: Whether the generated content is sufficiently creative.
- Timeliness: The recency of the generated results.
7) Contextual Memory Ability: This represents the model’s memory capabilities and the length of its contextual window.
8) Model Performance: This includes response speed, resource consumption, robustness, and stability (the ability to handle anomalies and unknown information reliably).
9) Human-likeness: This dimension evaluates whether the model truly exhibits “human-like” qualities, reaching a level of intelligence, including emotional analysis capabilities.
10) Multi-modal Capability: Finally, it assesses the model’s ability to process and generate across modalities, including text, images, videos, and speech.
2. How to Measure the Basic Capabilities of Large Models
It is well-known that the three most important elements for measuring the basic capabilities of large models are: algorithms, computational power, and data. More specifically, they include the following parts:
- Parameter Scale: This dimension measures the strength of the algorithm. A larger parameter scale indicates that the model can handle more complex problems and consider more dimensions, simply put, the stronger the model.
- Data Volume: Models operate on data, and the larger the underlying data volume, the better the model’s performance.
- Data Quality: Data quality includes the intrinsic value of the data and the degree of cleaning performed on the data. Data quality can be hierarchical; for example, user consumption data is more valuable than ordinary social attribute information. The higher the data value, the better the model’s performance. Additionally, the business’s data cleaning quality reflects in the precision of data labeling.
- Training Frequency: The more training iterations a model undergoes, the richer its experience, leading to better performance.
3. How to Evaluate Model Safety
In addition to assessing the capabilities of large models, safety considerations are also crucial. Even if a model is highly capable, if safety issues are not adequately addressed, large models cannot develop rapidly. We primarily evaluate model safety based on the following dimensions:
- Content Safety: This includes whether the generated content complies with safety management standards, social norms, and legal regulations.
- Ethical Standards: This includes whether the generated content contains bias or discrimination and whether it aligns with social values and ethical standards.
- Privacy and Copyright Protection: This includes the protection of personal and corporate privacy and compliance with copyright protection laws.
Lecture 11: Limitations of Large Models
1. The Hallucination Problem
The hallucination problem refers to the generation of information that appears reasonable but is actually incorrect or fabricated. In natural language processing, this may manifest as the model generating text or responses that seem coherent but lack truthfulness or accuracy. Currently, the hallucination problem is one of the main reasons users question the applicability of large models and why the results generated by large models are often difficult to use. It is also a challenging issue for AI applications.
What Causes Hallucinations in Large Models? The main sources are as follows:
- Overfitting Training Data: The model may have overfitted noise or erroneous information in the training data, leading to the generation of fabricated content.
- Presence of False Information in Training Data: If the training data does not adequately cover various real-world scenarios, the model may produce fabricated information in unfamiliar situations.
- Insufficient Consideration of Information Credibility: The model may not effectively assess the credibility of generated information, instead generating responses that seem reasonable but are actually fictitious.
Are There Solutions to Mitigate Hallucination Issues? Currently, potential ways to alleviate hallucination issues include:
- Using More Diverse Training Data: Introducing a more diverse and authentic training dataset to reduce the likelihood of the model overfitting erroneous information.
- Modeling Information Credibility and Increasing Verification Mechanisms: Incorporating components to estimate the credibility of generated information to filter or reduce the probability of generating fabricated content.
- External Verification Mechanisms: Utilizing external verification mechanisms or information sources to validate the content generated by the model, ensuring it aligns with the real world.
2. The Amnesia Problem
The amnesia problem refers to the situation where the model may forget previously mentioned information during long dialogues or complex contexts, resulting in inconsistencies and a lack of contextual integrity in generated content. The main causes of amnesia include:
- Model Context Memory Limitations: The model may be limited by its contextual memory capabilities, unable to effectively retain and utilize long-term dependencies.
- Missing Information in Training Data: If the training data lacks examples of long dialogues or complex contexts, the model may not learn the correct methods for retaining and retrieving information.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.